Working with SAP BI 7.0 Data Transfer Process (DTP)
Extraction Modes:
The data from source can be loaded into to target by using either Full or Delta mode.
Delta:
No initialization is required if extraction mode „Delta‟ selected. When the DTP is executed with this option for the first time, it brings all requests from the source into target and also sets the target in such way that it is initialized.

If you selected transfer mode Delta, you can define further parameters:
a. Only get delta once: It can select this option where the most recent data required in data target. In case delete overlapping request from data target have to select this option and use delete overlapping request process type in process chain. If used these setting then from the second loads it will delete the overlapping request from the data target and keeps only the last loaded request in data target.
b. Get all new data request by request: If don‟t select this option then the DTP will load all new requests from source into a single request. Have to select this option when the number of new requests is more in source and the amount of data volume is more. If selected this option then the DTP will load request by request from source and keep the same request in target.
In 3.x, in info package have an option Initialization without data transfer. This can be achieved in 7.x
by putting „No data transfer, delta status in source: Fetched‟.

Full: It behaves same like info package with option “Full”. It loads all data/requests from source into target.
Processing Mode:
These modes detail the steps that are carried out during DTP execution (e.g. Extraction, transformation, transfer etc). Processing mode also depends on the type of source.
The various types of processing modes are shown below:
1. Serial extraction, immediate parallel processing (asynchronous processing)
This option is most used in background processing when used in process chains. It processes the data packages in parallel.
2. Serial in dialog process (for debugging) (synchronous processing)
This option is used if we want to execute the DTP in dialog process and this is primarily used for debugging.
3. No data transfer; delta status in source: fetched
This option behaves exactly in the same way as explained above.
Temporary Data Storage Options in DTP:
In DTP, it can set in case to store the data temporarily in data loading process of any process like before extraction, before transformations. It will help in data analyzing for failed data requests.

Error Handling using DTP:
Options in error handling:

Deactivated:
Using this option error stack is not enabled at all. Hence for any failed records no data is written to the error stack. Thus if the data load fails, all the data needs to be reloaded again.
No update, no reporting:
If there is erroneous /incorrect record and we have this option enabled in the DTP, the load stops there with no data written to the error stack. Also this request will not be available for reporting. Correction would mean reloading the entire data again.
Valid Records Update, No reporting (Request Red):
Using this option all correct data is loaded to the cubes and incorrect data to the error stack. The data will not be available for reporting until the erroneous records are updated and QM status is manually set to green. The erroneous records can be updated using the error DTP.
Valid Records Updated, Reporting Possible (Request Green):
Using this option all correct data is loaded to the cubes and incorrect data to the error stack. The data will be available for reporting and process chains continue with the next steps. The erroneous records can be updated using the error DTP.
How to Handle Error Records in Error Stack:
Error stack:
A request-based table (PSA table) into which erroneous data records from a data transfer process is written. The error stack is based on the data source, that is, records from the source are written to the error stack.
At runtime, erroneous data records are written to an error stack if the error handling for the data transfer process is activated. You use the error stack to update the data to the target destination once the error is resolved.
In below example explained error data handling using error DTP in invalid characteristics data records:


This DTP load will create a new load request in target and load these modified records into target. Here, can see the modified 3 records loaded into target.

This defined key fields in semantic group‟s works as key fields of data package while reading data from
source system and error stock.

If need to put all records into a same data package which are having same keys from loading source system. In this case select semantic keys in DTP those are required as keys in data package.
In semantic group the key fields will be available if selected the error handling option „Valid Records Update, No reporting (Request Red)‟ or „Valid Records Updated, Reporting Possible (Request Green)‟
DTP Settings to Increase the Loading Performance
1. Number of Parallel Process:
We can define the number of processes to be used in the DTP.
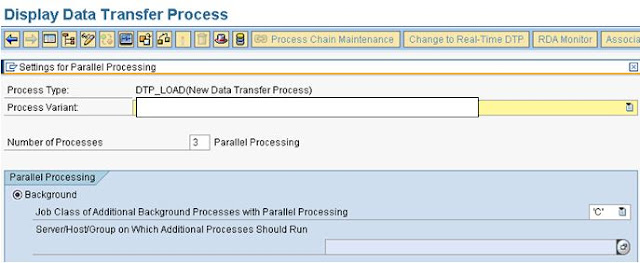
Here defined 3, hence 3 data packages are processed in parallel.
2. Don’t Load Large Value Data by Sing DTP Load Request:
To avoid load large volume data into a single DTP request select Get all new data request by request in extraction tab.
3. Full Load to Target:
In case full load into data target from DSO or first load from DSO to target always loads from Active table as it contains less number of records with Change log table.

4. Load from Info Cube to Other Target:
In case reading data from info cube to open hub destination it is best to use extraction from Aggregates. If select this option it reads first the aggregates tables instead of E and F table in case cube contains any aggregates.
Handle Duplicate Records
In case load to DSO, we can eliminate duplicate records by selecting option "Unique Data Records". If loading to master data it can be handled by selecting “handling duplicate record keys” option in DTP.
If you select this option then It will overwrite the master data record in case it time independent and will create multiple entries in case dime dependent master data.

Extraction Modes:
The data from source can be loaded into to target by using either Full or Delta mode.
Delta:
No initialization is required if extraction mode „Delta‟ selected. When the DTP is executed with this option for the first time, it brings all requests from the source into target and also sets the target in such way that it is initialized.

If you selected transfer mode Delta, you can define further parameters:
a. Only get delta once: It can select this option where the most recent data required in data target. In case delete overlapping request from data target have to select this option and use delete overlapping request process type in process chain. If used these setting then from the second loads it will delete the overlapping request from the data target and keeps only the last loaded request in data target.
b. Get all new data request by request: If don‟t select this option then the DTP will load all new requests from source into a single request. Have to select this option when the number of new requests is more in source and the amount of data volume is more. If selected this option then the DTP will load request by request from source and keep the same request in target.
In 3.x, in info package have an option Initialization without data transfer. This can be achieved in 7.x
by putting „No data transfer, delta status in source: Fetched‟.

Full: It behaves same like info package with option “Full”. It loads all data/requests from source into target.
Processing Mode:
These modes detail the steps that are carried out during DTP execution (e.g. Extraction, transformation, transfer etc). Processing mode also depends on the type of source.
The various types of processing modes are shown below:
1. Serial extraction, immediate parallel processing (asynchronous processing)
This option is most used in background processing when used in process chains. It processes the data packages in parallel.
2. Serial in dialog process (for debugging) (synchronous processing)
This option is used if we want to execute the DTP in dialog process and this is primarily used for debugging.
3. No data transfer; delta status in source: fetched
This option behaves exactly in the same way as explained above.
Temporary Data Storage Options in DTP:
In DTP, it can set in case to store the data temporarily in data loading process of any process like before extraction, before transformations. It will help in data analyzing for failed data requests.

Error Handling using DTP:
Options in error handling:

Deactivated:
Using this option error stack is not enabled at all. Hence for any failed records no data is written to the error stack. Thus if the data load fails, all the data needs to be reloaded again.
No update, no reporting:
If there is erroneous /incorrect record and we have this option enabled in the DTP, the load stops there with no data written to the error stack. Also this request will not be available for reporting. Correction would mean reloading the entire data again.
Valid Records Update, No reporting (Request Red):
Using this option all correct data is loaded to the cubes and incorrect data to the error stack. The data will not be available for reporting until the erroneous records are updated and QM status is manually set to green. The erroneous records can be updated using the error DTP.
Valid Records Updated, Reporting Possible (Request Green):
Using this option all correct data is loaded to the cubes and incorrect data to the error stack. The data will be available for reporting and process chains continue with the next steps. The erroneous records can be updated using the error DTP.
How to Handle Error Records in Error Stack:
Error stack:
A request-based table (PSA table) into which erroneous data records from a data transfer process is written. The error stack is based on the data source, that is, records from the source are written to the error stack.
At runtime, erroneous data records are written to an error stack if the error handling for the data transfer process is activated. You use the error stack to update the data to the target destination once the error is resolved.
In below example explained error data handling using error DTP in invalid characteristics data records:

Modify the error record in error stack by clicking on edit button.

This DTP load will create a new load request in target and load these modified records into target. Here, can see the modified 3 records loaded into target.

Importance of Semantic Groups
This defined key fields in semantic group‟s works as key fields of data package while reading data from
source system and error stock.

If need to put all records into a same data package which are having same keys from loading source system. In this case select semantic keys in DTP those are required as keys in data package.
In semantic group the key fields will be available if selected the error handling option „Valid Records Update, No reporting (Request Red)‟ or „Valid Records Updated, Reporting Possible (Request Green)‟
DTP Settings to Increase the Loading Performance
1. Number of Parallel Process:
We can define the number of processes to be used in the DTP.
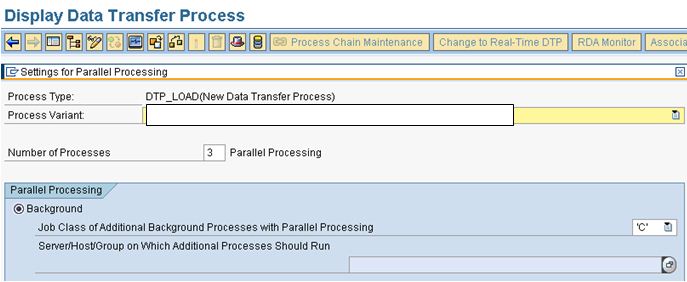
Here defined 3, hence 3 data packages are processed in parallel.
2. Don’t Load Large Value Data by Sing DTP Load Request:
To avoid load large volume data into a single DTP request select Get all new data request by request in extraction tab.
3. Full Load to Target:
In case full load into data target from DSO or first load from DSO to target always loads from Active table as it contains less number of records with Change log table.

4. Load from Info Cube to Other Target:
In case reading data from info cube to open hub destination it is best to use extraction from Aggregates. If select this option it reads first the aggregates tables instead of E and F table in case cube contains any aggregates.
Handle Duplicate Records
In case load to DSO, we can eliminate duplicate records by selecting option "Unique Data Records". If loading to master data it can be handled by selecting “handling duplicate record keys” option in DTP.
If you select this option then It will overwrite the master data record in case it time independent and will create multiple entries in case dime dependent master data.

There are some really loved reading your blog. It was very well authored and easy to understand. Unlike additional blogs I have read which are really not good. I also found your posts very interesting. In fact after reading, I had to go show it to my friend and he enjoyed it as well!
ReplyDeletesap bi training in hyderabad
Nice Article. Useful Information for the BI people who wants to know more about SAP BI, SAP BW. Do you want free demo on SAP BW Implementation, then please contact SAP BW Services
ReplyDeleteHey,
ReplyDeleteI noticed your Article. I just loved it.
Experience one of the authorized sap training institute in hyderabad and take your carrier to next level.
If you like it feel free and share it.
Cheers,
Varsha.